
Does working as a researcher cause your eyesight to become strained, your back to become hunched, and your social life to become rather limited? Or is this just an association? The fact that I’m even asking this question probably suggests that I need to get out more. But the question of causality arises frequently in population research, as well as our ‘real’ lives, so we thought that an introduction to the topic might make a useful and thought-provoking post. The only problem is where to start…
The example of smoking and lung cancer
The history of research on smoking and lung cancer includes conspiracy, corporate denial, and some excellent lessons for researchers. In 2004, Richard Doll wrote a nine page report providing evidence that smoking causes cancer. In itself, this may seem unremarkable, and perhaps a little late, (didn’t everyone know this in 2004?). But Doll’s report was the follow-up for research that he had begun more than 50 years earlier. And he was over 90 when it was published! (Sadly, he died the year afterwards aged 92.)
The problem of confounding
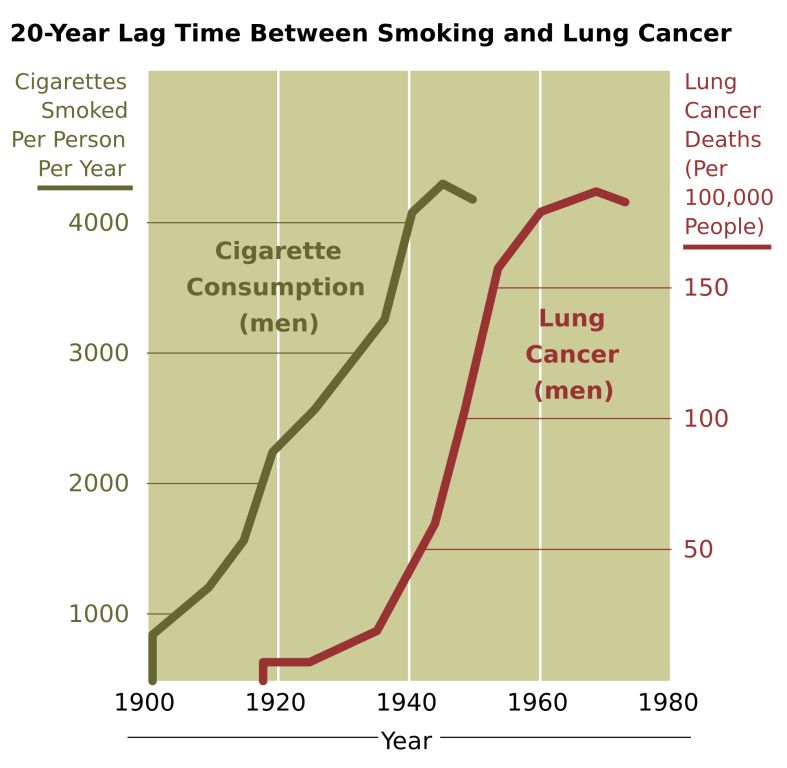
Figure 1: US data on smoking and lung cancer
There are different types of evidence that suggest a causal link between smoking and lung cancer. The trend in US lung cancer rates was pre-empted by the trend in US smoking rates over much of the 20th Century (see Figure 1). There is a several hundred year history of evidence that suggests a link between smoking and cancer. But it wasn’t until 1950 that Doll and colleagues found convincing evidence that suggested smokers were more likely to die of lung cancer than non-smokers (in the US and the UK). But was this causal evidence? There were, and still are, a range of differences between smokers and non-smokers, and any one of these differences could be the cause of lung cancer, rather than smoking. For example, people who smoke are less likely to exercise, so exercise might be a confounder in the relationship between smoking and lung cancer. This is because people who do not exercise are more likely to be ‘selected into’ smoking (a form of selection bias), and are therefore systematically different from non-smokers. Causal inference can be problematic if research does not consider all the factors that might be responsible for confounding or selection. Even after Doll’s work was published, the statistician Ronald Fisher was one of several notable critics who argued that the link between smoking and cancer was explained by other factors, and therefore a spurious association (another term for confounding). For a discussion and references see here.
Randomized experiments
One way for Doll to avoid the problems of confounding and selection was to compare two groups of people who were exactly the same, except for their smoking behaviour, and then see which group was more likely to develop lung cancer. In theory, he could have achieved this by randomizing smoking. Of course, this was neither possible nor ethical, even in the 1950s. However, if we imagine an alternative universe where it was possible, then Doll could have carried out something similar to a modern randomized drug trial, such that smoking would be the only difference between the groups who were treated (smokers) and those who were controls (non-smokers). The reason why randomization is seen by many as the best tool for investigating causality is essentially because of the balance that randomization creates, such that each group has the same characteristics (on average), and the only difference between them is with regard to treatment status.
Counterfactuals and potential outcomes
It was the same Ronald Fisher, the critic of Doll’s research, who almost single-handedly laid the foundations for the design and analysis of randomized experiments (although the origins of randomization are a little more nuanced than this). There was, and still is, much debate about causal inference based on experiments, but as outlined by Paul Holland, the work of Fisher and Jerzy Neyman helped to lay the foundation for the potential outcomes framework, which is particularly useful for understanding and researching causality. This framework is based on a comparison of counterfactuals, which can be thought of as ‘what if…’ statements (e.g. ‘what if Hitler had been assassinated?’). Described in simple terms, thinking about potential outcomes involves considering what would happen if we went backwards in time, changed one aspect of someone’s life, and then studied what happened to them. For example, what would happen to the treated (e.g. those given a drug), if they did not receive the treatment (i.e. they were not given the drug)? Similarly, what would happen to the controls if they were treated? Of course, it is impossible for one patient to take a drug and not take a drug, but the potential outcomes framework invokes this kind of hypothetical thought-experiment. If I knew my potential outcomes, the outcomes that I would experience with and without the drug, then I would know my individual causal effect. However, we only know one of the outcomes for each individual (assuming treatment is binary), so we need to approximate the other potential outcome using information about other people. (This is one reason why causal estimates are ‘averages’ and not calculated for individuals).
Research design in non-experimental settings
Returning to the smoking example, Doll could not randomize smoking. Instead, he had to decide the ideal non-experimental (observational) study design. There is not enough space here to summarise his 1954 paper, except to say that it was a large-sample prospective cohort study of doctors (who are quite similar to each other – and hence more likely to be balanced than the general population). He also used standardisation in order to compare similar groups of smokers and non-smokers. By contemporary standards, his statistical analysis was relatively simple. However, as argued by David Freedman, an investigation of causality rests less upon statistics than upon thoughtful research design, including the hard work of collecting appropriate data.
Collaboration and bodies of evidence
It is important to acknowledge that Doll was not working alone. In fact, the co-author of Doll’s original 1954 paper was Austin Bradford Hill, a man who has more than one connection to the history of causal inference. Hill has been credited with designing the first widely publicized clinical trial (see here), and is also famous for his paper on association and causation. This paper offers guidance on how researchers deduce causation from data (and is discussed here and here). As Doll and Hill both understood, one study is not enough to demonstrate causality. It is only through weight of consistent evidence that we can argue causality has been ‘proven’.
Modern methods
It is interesting to compare Doll and Hill’s analysis in 1954 to many contemporary papers, which tend to rely on more complicated statistical modelling. We might wonder ‘what if’ they tried to publish a similar study today. On the one hand, it could be argued that the contemporary researcher benefits from a bountiful buffet of techniques and approaches, including: subclassification, matching (e.g. the propensity score), difference-in-difference, selection models, natural experiments, twin studies, instrumental variables, regression discontinuity, synthetic control, causal diagrams, mediation analysis, g-computation, and causal inference without counterfactuals. On the other hand, there is considerable debate about causality across the social sciences. The contemporary reliance on statistical modelling has been criticised, and it has been argued that randomized control trials are not the ‘gold standard’, that more value should be placed on descriptive research, and that causal research is more about measuring the size of ‘effects’ than it is about showing whether a relationship is either causal, or not. Often, researchers seek to evaluate whether an intervention or policy had a causal effect, but in order for this information to be of value, it is crucial to understand whether this effect would be repeated if the intervention were applied to a different context (an issue that relates to debates about internal and external validity). It is clear that policy analysis involves considerable uncertainty. For example, the evaluation of policies to ban smoking in cars requires many factors to be considered, beyond causal estimates of policy effectiveness.
Further reading
Perspectives on causality vary across the social sciences, and it is hard to recognize the many contributions that have been made to the topic. A lot of the references given here concern causal inference and epidemiology, but research can be found across disciplines, including: philosophy, statistics, economics, political science, sociology, and psychology. And finally, this is a population blog, so I would highly recommend reading the following:
– On Causation in Demography: Issues and Illustrations
– Causal analysis in population studies: concepts, methods, applications
– ‘Divorce Effects’ and Causality in the Social Sciences
– Remarks on the analysis of causal relationships in population research

Well written and informative post! I’d like to add that in population studies, we often study relations at aggregate levels (e.g. countries, regions). In terms of causality this adds the additional dimension of compostion.While in RCTs you already face observed and unobserved heterogeneity of the participants, in country comparisons you have to account for the observed and unobserved heterogeneity of the countries but also simultaneously of the (change of the) composition of the observed and unobserved heterogeneity of their inhabitants. Any effect could be a pure compositional effect and establishing a causal link becomes close to impossible…
Going back to descriptive research might be a solution, but without any findings on causal relations there is not much left to advice policy makers. If demographers would forgo to do such studies, I am sure economist are more than happy to fill this gap and collect the grant money ;-).
[…] and this is likely to affect demography as well. The epidemiological revolution is, in fact, a causal inference revolution. In this post, I describe G-computation, a technique which is used by scientists […]
[…] effects, the issue of spurious relations between research variables, the problem of identifying causality, and selection bias. From cross-sectional data analysis, it is often difficult to address […]